2
Decision Trees
2.1 Introduction
Decision Tree (DT) is a versatile ML algorithm which can perform both classification and regression tasks, and even multi-output tasks, capable of fitting complex datasets. They are classified as a non-parametric supervised learning algorithm, which is utilised for both classification and regression tasks.
It has a hierarchical tree structure, consisting of a root node, branches, internal nodes and leaf nodes. DT s are also the fundamental components of random forests, which are among the most powerful ML algorithms available today. Some of the applications include:
- Loan Approval in Banking
-
Banks use DT s to assess whether a loan application should be approved. The decision is based on factors such as credit score, income, and loan history. This helps predict approval or rejection and enables quick and reliable decisions [1], [2].
- Medical Diagnosis
-
In healthcare they assist in diagnosing diseases. For example, they can predict whether a patient has diabetes based on clinical data like glucose levels, Body-Mass Index (BMI) and blood pressure [3]. This helps classify patients into diabetic or non-diabetic categories, supporting early diagnosis and treatment [4].
- Predicting Exam Results in Education
-
Educational institutions use to predict whether a student will pass or fail based on factors like attendance, study time and past grades. This helps teachers identify at-risk students and offer targeted support [5], [6].
- Customer Churn Prediction
-
Companies use DT s to predict whether a customer will leave or stay based on behaviour patterns, purchase history, and interactions. This allows businesses to take proactive steps to retain customers [7].
- Fraud Detection
-
In finance, DT s are used to detect fraudulent activities, such as credit card fraud [8]. By analysing past transaction data and patterns, DT s can identify suspicious activities and flag them for further investigation [9].
In this chapter we will start by discussing how to train, visualise, and make predictions with
DT
s. Then
we will go through the
Classification and Regression Tree (CART)
training algorithm used by scikit-learn, and we will explore how to regularise trees and use them for regression
tasks.
2.1.1 Advantages and Disadvantages
Before we start with our chapter on DT , lets list down the advantages it has over other methods:
- Easy to Understand
-
DT s are visual which makes it easy to follow the decision-making process
- Versatility
-
Can be used for both classification and regression problems.
- No Need for Feature Scaling
-
Unlike many ML models, it doesn’t require us to scale or normalise our data.
- Handles Non-linear Relationships
-
It capture complex, non-linear relationships between features and outcomes effectively.
- Interpretability
-
The tree structure is easy to interpret helps in allowing users to understand the reasoning behind each decision.
- Handles Missing Data
-
It can handle missing values by using strategies like assigning the most common value or ignoring missing data during splits.
Of course, as with every method, there are it’s disadvantages which are:
- Over-fitting
-
They can over-fit the training data if they are too deep which means they memorise the data instead of learning general patterns. This leads to poor performance on unseen data.
- Instability
-
It can be unstable which means that small changes in the data may lead to significant differences in the tree structure and predictions.
- Bias towards Features with Many Categories
-
It can become biased toward features with many distinct values which focuses too much on them and potentially missing other important features which can reduce prediction accuracy.
- Difficulty in Capturing Complex Interactions
-
DT s may struggle to capture complex interactions between features which helps in making them less effective for certain types of data.
- Computationally Expensive for Large Datasets
-
For large datasets, building and pruning a DT can be computationally intensive, especially as the tree depth increases.
Information : White v. Black Box
DT s are intuitive, and their decisions are easy to interpret. Such models are often called white box models. In contrast, random forests and neural networks are generally considered black box models. They make great predictions, and we can easily check the calculations that they performed to make these predictions, however, it is usually hard to explain in simple terms why the predictions were made.
For example, if a neural network says that a particular person appears in a picture, it is hard to know what contributed to this prediction: Did the model recognise that person’s eyes? Their mouth? Their nose? Their shoes? Or even the couch that they were sitting on? Conversely, DT s provide nice, simple classification rules that can even be applied manually if need be (e.g., for flower classification). The field of interpretable ML aims at creating ML systems that can explain their decisions in a way humans can understand. This is important in many domains-for example, to ensure the system does not make unfair decisions.
2.2 Training and Visualising Decision Trees
To understand
DT
s, let’s build one and take a look at how it makes predictions. The following code
trains a DecisionTreeClassifier
on the iris dataset:
from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier iris = load_iris(as_frame=True) X_iris = iris.data[["petal length (cm)", "petal width (cm)"]].values y_iris = iris.target tree_clf = DecisionTreeClassifier(max_depth=2, random_state=42) tree_clf.fit(X_iris, y_iris)
We can visualise the trained
DT
by first using the export_graphviz()
function to output a graph
definition file called iris_tree.dot
:
If we are using a Jupyter Notebook to study, we can use graphviz.Source.from_file()
to load and
display the file inline such as given below:
Information : Graphviz & DOT
Graphviz (short for Graph Visualisation Software) is a package of open-source tools for creating graphs. It takes text input in DOT format, generates images.
DOT is a graph description language. DOT files are usually with .gv
filename extension.
2.3 Making Predictions
Let’s see how the tree represented in Fig. 2.1 makes predictions.
Suppose we find an iris flower and want to classify it based on its
class=setosa).
Now
suppose
we
find
another
flower,
and
this
time
the
petal
length
is
greater
than
2,45
cm
.
We
again
start
at
the
root
but
now
move
down
to
its
right
child
node
is the petal width smaller than 1,75 cm ?
If it is, then our flower is most likely an
One of the many qualities of DT s is that they require very little data preparation. In fact, they don’t require feature scaling or centring at all.
A node’s samples attribute counts how many training instances it applies to.
For example, 100 training instances have a petal length greater than 2,45 cm (depth 1, right), and of those 100, 54 have a petal width smaller than 1,75 cm (depth 2, left).
A node’s value attribute tells us how many training instances of each class this node applies to.
For example, the bottom-right node applies to 0 Iris setosa, 1 Iris versicolor, and 45 Iris virginica.
Finally,
a
node’s
gini
attribute
measures
its
Gini
impurity
,
named
after
Corrado
Gini

2.3.1 Gini Impurity
Gini Impurity is a measurement used to build DT s to determine how the features of a dataset should split nodes to form the tree. More precisely, the Gini Impurity of a dataset is a number between 0 - 0.5, which indicates the likelihood of new, random data being misclassified if it were given a random class label according to the class distribution in the dataset.
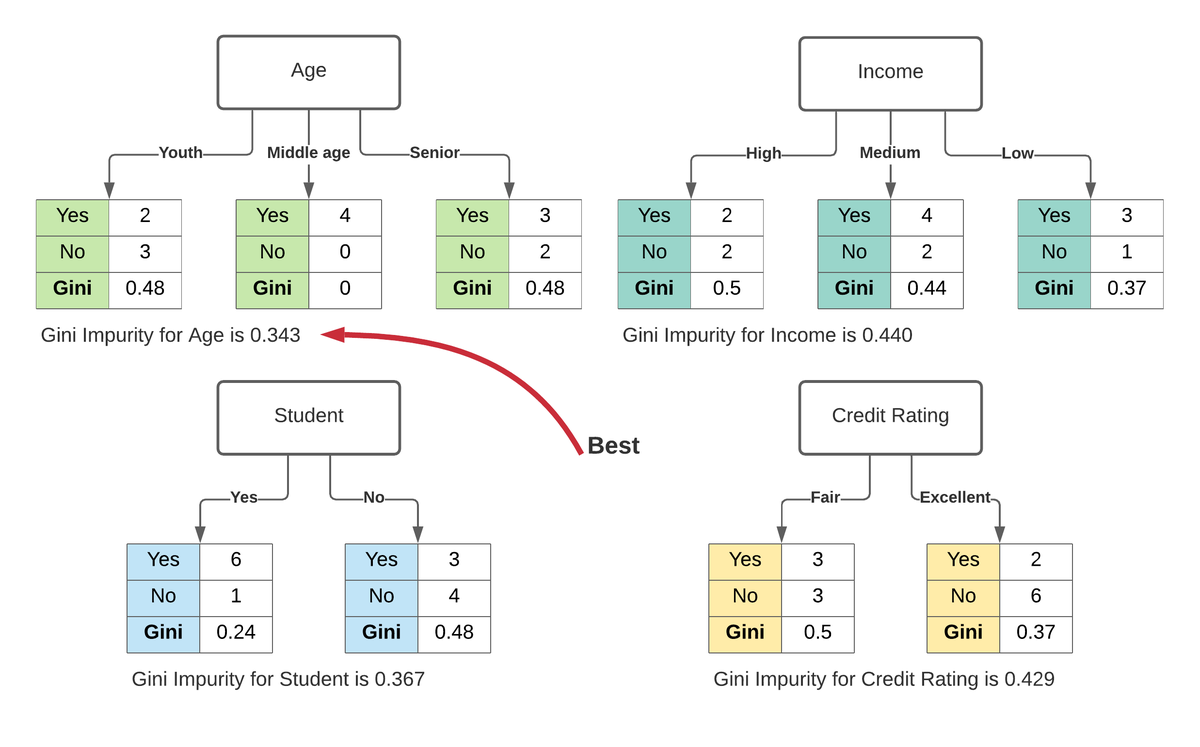
For example, say we want to build a classifier which determines if someone will default on their credit card. We
have some labelled data with features, such as bins for age, income, credit rating, and whether or not each
person is a student. For us to find the best feature for the first split of the tree
-
default ("yes"), or
-
didn’t default ("no").
This calculation would measure the impurity of the split, and the feature with the lowest impurity would determine the best feature for splitting the current node. This process would continue for each subsequent node using the remaining features.
In Fig. 2.2 , age has minimum Gini impurity, so age is selected as the root in the decision tree.
A node is said to be
pure
(gini=0) if all training instances belong to the same class.
Going back to our
Mathematically we can define the Gini impurity as:
| (2.1) |
where is the Gini impurity of the node, is the ratio of class instances among the training instances in the node. Using this definition we can calculate the depth-2 left node as:
scikit-learn
uses
the
CART
algorithm,
which
produces
only
binary
trees
,
meaning
trees
where
split
nodes
always
have
exactly
two
However, other algorithms, such as ID3,
Fig.
2.3
shows this
DT
’s decision boundaries. The thick vertical line represents the decision boundary of the root node (depth 0)
with petal length = 2,45cm. Given the left hand area is pure (only
Given max_depth
was set to 2, the
DT
stops right there. If we set max_depth
to 3, then
the two depth-2 nodes would each add another decision boundary.

The tree structure, including all the information shown in Figure
2.1
, is available via the classifier’s tree_
attribute. For more
information, type help(tree_clf.tree_).
2.3.2 Estimating Class Probabilities
A DT can also estimate the probability which an instance belongs to a particular class . First, it traverses the tree to find the leaf node for this instance, and then it returns the ratio of training instances of class in this node.
For example, suppose we have found a flower whose petals are 5cm long and 1,5cm wide. The corresponding leaf node is the depth-2 left node, so the DT outputs the following probabilities:
-
0% for Iris setosa (0/54),
-
90.7% for Iris versicolor (49/54), and
-
9.3% for Iris virginica (5/54).
If we ask it to predict the class, it outputs Iris versicolor (class 1) because it has
Notice the estimated probabilities would be identical anywhere else in the bottom-right rectangle of Fig. 2.1 , for example, if the petals were 6cm long and 1,5cm wide.
2.4 The CART Training Algorithm
CART
is a predictive algorithm used for explaining how the target variable’s values can be predicted based on other matters. It is
a
DT
where each fork is split into a predictor variable and each node has a prediction for the target variable at the end. The
three
- Tree structure
-
CART builds a tree-like structure consisting of nodes and branches. The nodes represent different decision points, and the branches represent the possible outcomes of those decisions. The leaf nodes in the tree contain a predicted class label or value for the target variable.
- Splitting Criteria
-
CART uses a greedy approach to split the data at each node. It evaluates all possible splits and selects the one that best reduces the impurity of the resulting subsets. For classification tasks, CART uses Gini impurity as the splitting criterion. The lower the Gini impurity, the more pure the subset is. For regression tasks, CART uses residual reduction as the splitting criterion. The lower the residual reduction, the better the fit of the model to the data.
- Pruning
-
To prevent over-fitting of the data, pruning is a technique used to remove the nodes that contribute little to the model accuracy. Cost complexity pruning and information gain pruning are two popular pruning techniques. Cost complexity pruning involves calculating the cost of each node and removing nodes that have a negative cost. Information gain pruning involves calculating the information gain of each node and removing nodes that have a low information gain.
scikit-learn
uses
the
CART
algorithm
to
train
DT
s
(also
called
growing
trees).
The
algorithm
works
by
splitting
the
training
set
into
two
How does it choose and ?
It searches for the pair that produces the purest subsets, weighted by their size. Eq. ( 2.2 ) gives the cost function that the algorithm tries to minimise.
| (2.2) |
Once
the
CART
algorithm
successfully
splits
the
training
set
in
two,
it
splits
the
subsets
using
the
same
logic,
then
the
sub-subsets,
and
so
on,
recursively.
It
stops
its
recursive
behaviour
once
it
reaches
the
maximum
depth,
max_depth
hyperparameter.
or
if
it
cannot
find
a
split
that
will
reduce
impurity.
A few other hyperparameters control additional stopping conditions:
min_samples_split, min_samples_leaf, min_weight_fraction_leaf, max_leaf_nodes.
CART algorithm is a greedy algorithm . This means it greedily searches for an optimum split at the top level, then repeats the process at each subsequent level. It does not whether the split will lead to the lowest possible impurity several levels down. A greedy algorithm often produces a solution that’s reasonably good but not guaranteed to be optimal.
2.4.1 Gini Impurity v. Information Entropy
By default, the DecisionTreeClassifier
class uses the
Gini impurity
measure, but we can select the entropy impurity measure
instead by setting the criterion hyperparameter to
Information : Entropy: A Measure of Disorder
The concept of entropy originated in thermodynamics as a measure of molecular disorder: entropy approaches zero when molecules are still and well ordered.
Entropy
later
spread
to
a
wide
variety
of
domains,
including
in
Shannon’s

In ML , entropy is frequently used as a measurement of impurity, a set’s entropy is zero when it contains instances of only one class. Eq. ( 2.3 ) shows the definition of the entropy of the node.
For example, the depth-2 left node in Fig. 2.1 has an entropy equal to:
And the general equation for entropy could be written as:
| (2.3) |
So, which one to use? Gini impurity or entropy?
Most of the time it does not make a big difference as they lead to similar trees. Gini impurity is slightly faster to compute, so it is a good default. However, when they differ, Gini impurity tends to isolate the most frequent class in its own branch of the tree, while entropy tends to produce slightly more balanced trees.
2.4.2 Regularisation Hyperparameters
DT
s
make
very
few
assumptions
about
the
training
data.
Such
a
model
is
often
called
a
non-parametric
model,
not
because
it
does
not
have
any
parameters
In contrast, a parametric model, such as a linear model, has a predetermined number of parameters, so its degree of freedom is limited, reducing the risk of over-fitting.
This, however, increases the risk of under-fitting.
To avoid over-fitting the training data, we need to restrict the DT ’s freedom during training. As we should know by now, this is called regularisation .
The regularisation hyperparameters depend on the algorithm used, but generally we can at least restrict the
maximum depth of the
DT
. In scikit-learn, this is controlled by the max_depth
hyperparameter. The default
value is None, which means unlimited. Reducing max_depth
will regularise the model and thus reduce the risk of
over-fitting.
The DecisionTreeClassifier
class has a few other parameters that similarly restrict the shape of the
DT
:
-
max_features -
Maximum number of features that are evaluated for splitting at each node
-
max_leaf_nodes -
Maximum number of leaf nodes
-
min_samples_split -
Minimum number of samples a node must have before it can be split
-
min_samples_leaf -
Minimum number of samples a leaf node must have to be created
-
min_weight_fraction_leaf -
Same as
min_samples_leafbut expressed as a fraction of the total number of weighted instances.
Increasing min_*
or reducing max_*
hyperparameters will regularise the model.
Information : Other Methods of Training
Other algorithms work by first training the DT without restrictions, then pruning unnecessary nodes. A node whose children are all leaf nodes is considered unnecessary if the purity improvement it provides is not statistically significant. Standard statistical tests, such as the test (chi-squared test), are used to estimate the probability that the improvement is purely the result of chance (which is called the null hypothesis). If this probability, called the p-value, is higher than a given threshold (typically 5%, controlled by a hyperparameter), then the node is considered unnecessary and its children are deleted. The pruning continues until all unnecessary nodes have been pruned.
Let’s test regularisation on the moons dataset, introduced previously. We’ll train one
DT
without regularisation,
and another with min_samples_leaf=5. Here’s the code with
Fig.
2.4
showing the decision boundaries of each
tree.
from sklearn.datasets import make_moons X_moons, y_moons = make_moons(n_samples=150, noise=0.2, random_state=42) tree_clf1 = DecisionTreeClassifier(random_state=42) tree_clf2 = DecisionTreeClassifier(min_samples_leaf=5, random_state=42) tree_clf1.fit(X_moons, y_moons) tree_clf2.fit(X_moons, y_moons)

The unregulated model on the left is clearly over-fitting, and the regularised model on the right will probably generalise better. We can verify this by evaluating both trees on a test set generated using a different random seed:
As we can see, the tree has a better accuracy on the test set.
2.5 Regression
DT
s are also capable of performing regression tasks. Let’s build a regression tree with the DecisionTreeRegressor
class, training it
on a noisy quadratic dataset with max_depth=2
with the resulting tree being represented in
Fig.
2.5
.

This tree looks very similar to the classification tree built earlier. The main difference is that instead of predicting a class in each node, it predicts a value .

For example, say we want to make a prediction for a new instance with
= 0.2. The root
node asks whether
.
As it is not, the algorithm goes to the right child node, which asks whether
. Since it
is, the algorithm goes to the left child node. This is a leaf node, and it predicts value=0.111. This prediction is the average target
value of the 110 training instances associated with this leaf node, and results in a mean squared error equal to 0.015 over these
110 instances.
This model’s predictions are represented on the left in
Fig.
2.6
. If we set max_depth=3, we get the predictions represented on the
right. Notice how the predicted value for each region is always the average target value of the instances in that region. The
algorithm splits each region in a way that makes most training instances as close as possible to that predicted
value.
The CART algorithm works as described earlier, except that instead of trying to split the training set in a way that minimises impurity, it now tries to split the training set in a way that minimises the Mean Square Error (MSE) . To get a better feel of the underlying mathematics, Eq. ( 2.4 ) shows the cost function that the algorithm tries to minimise:
| (2.4) |
Just
like
for
classification
tasks,
DT
s
are
prone
to
over-fitting
when
dealing
with
regression
tasks.
Without
any
regularization,
As can clearly be seen, these predictions are over-fitting the training set very badly. Setting min_samples_leaf=10
results in a
significantly more reasonable model, represented on the right in
Fig.
2.7
.

2.6 Sensitivity to Axis Orientation
DT
s
have
a
lot
going
for
them
given
they
are
relatively
easy
to
understand
and
interpret,
simple
to
use,
versatile,
and
powerful.
However,
they
do
have
a
few
limitations.
First,
as
we
may
have
noticed,
DT
s
love
orthogonal
decision
boundaries,

For example, Fig. 2.8 shows a simple linearly separable dataset where on the left, a DT can split it easily, while on the right, after the dataset is rotated by 45 degrees, the decision boundary looks unnecessarily convoluted. Although both DT s fit the training set perfectly, it is very likely that the model on the right will not generalise well.
One way to limit this problem is to scale the data, then apply a principal component analysis transformation. We will look at Principal Component Analysis (PCA) in detail later, but for now we only need to know that it rotates the data in a way that reduces the correlation between the features, which often makes things easier for trees.
Let’s create a small pipeline that scales the data and rotates it using
PCA
, then, continue on to train a DecisionTreeClassifier
on that data.
from sklearn.decomposition import PCA from sklearn.pipeline import make_pipeline from sklearn.preprocessing import StandardScaler pca_pipeline = make_pipeline(StandardScaler(), PCA()) X_iris_rotated = pca_pipeline.fit_transform(X_iris) tree_clf_pca = DecisionTreeClassifier(max_depth=2, random_state=42) tree_clf_pca.fit(X_iris_rotated, y_iris)
Fig.
2.9
shows the decision boundaries of that tree and as we can see, the rotation makes it possible to fit the dataset pretty well
using only one

Information : The Problem of High Variance
More generally, the primary issue with DT s is that they have high variance where small changes to the hyperparameters or to the data may produce very different models.
In fact, given the training algorithm used by scikit-learn
is stochastic-it randomly selects the set of features to
evaluate at each node-even retraining the same
DT
on the exact same data may produce a very different model,
such as the one represented in
Fig.
2.10
, unless we set the random_state
hyperparameter.
As we can see, it looks very different from the previous DT , shown in Fig. 2.1 .

Luckily, by averaging predictions over many trees, it’s possible to reduce variance significantly. Such an ensemble is called a Random Forest (RF) , and it’s one of the most powerful types of models available today.